 chatgpt图片识别描述功能
chatgpt图片识别描述功能
# chatGPT图片识别/描述
you can use dall-e-3 to generate images and gpt-4-vision-preview to understand images.
# 模型
使用gpt-4-1106-vision-preview
- GPT-4 Turbo with vision is the same as the GPT-4 Turbo preview model and performs equally as well on text tasks but has vision capabilities added
# 价格
https://openai.com/pricing

# 分辨率选择:
720p or 1080p?
从下面的计算对比可以看到,因为取整的缘故,720p和1080p的图一样的价格. 因为1080的图会被openai二次压缩到768*1365.
那么选一个768的整数倍:
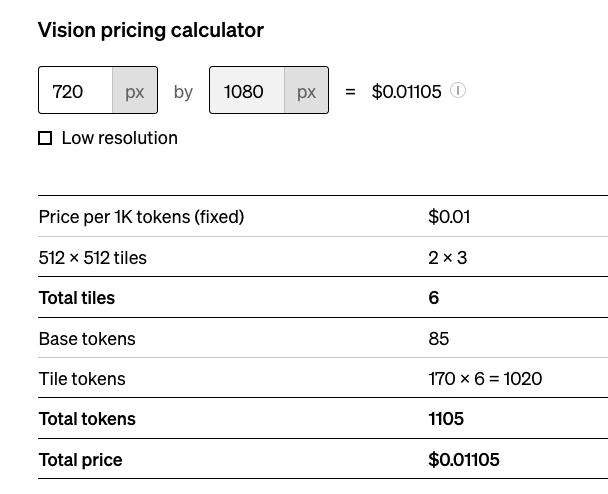
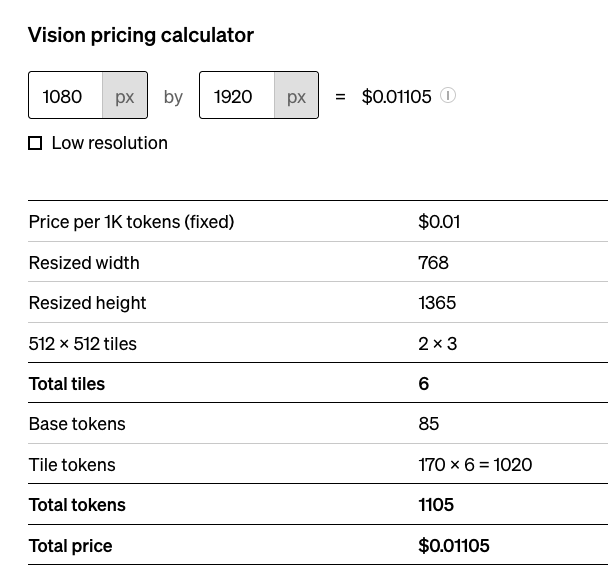
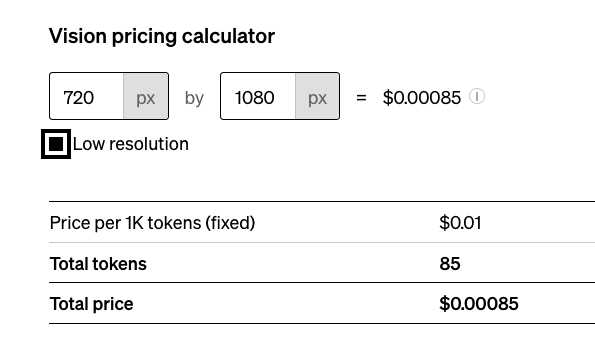
而勾选了low resolution时,非常便宜,应该是会压缩到非常小:
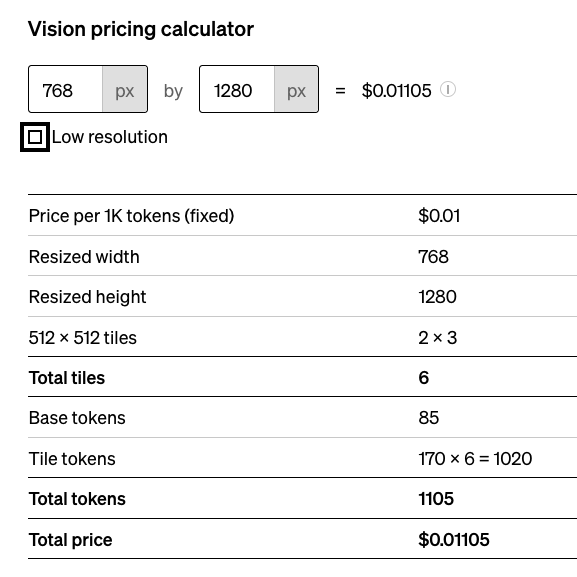
比较合适的分辨率: 768*1280
也就是短边压缩到768,长边等比压缩.
# 接口
https://platform.openai.com/docs/guides/vision
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What’s in this image?"
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
"detail": "high"
}
}
]
}
],
"max_tokens": 300
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# detail参数:
For low res mode, we expect a 512px x 512px image. For high res mode, the short side of the image should be less than 768px and the long side should be less than 2,000px.
All images with detail: low cost 85 tokens each. detail: high images are first scaled to fit within a 2048 x 2048 square, maintaining their aspect ratio. Then, they are scaled such that the shortest side of the image is 768px long. Finally, we count how many 512px squares the image consists of. Each of those squares costs 170 tokens. Another 85 tokens are always added to the final total.

# 交互设计
拍照/相册选图
-> 提供裁剪功能
->最后压缩到768*xxx, 如果小于768, 则压缩到515,且请求时设置detail为low
->上传到自己的oss,拿到url
->调用open ai的接口, 添加prompt为:
What’s in this image?
how many people in the image?
...
2
3
# 注意事项
图像前置处理:
方向要正确
不要vr图,鱼眼图
文本识别只能处理拉丁语系的语言,不能处理中文,日文,韩文
# 代码库
图片裁剪:
https://pub.dev/packages/crop_your_image